Forum mentions & musings re. the use of PICAXE generated Hellscreiber for "eye decoded" weak signal comms has arisen before (Haxby 2005 etc), but I've decided to give it a decent workout, with modulation of a low power 27.145 MHz transmitter in mind.
For those who've just come in, fuzzy mode "Hell" dates from 1929 & remains legendary for weak signal decoding, & is particularly well suited for very slow comms- often under the most ugly noise. Thanks to sound card decoding software Hellscreiber has had a terrific revitalisation with radio hams in the last decade, & new submodes have developed. See Murray's magnificent site=> http://www.qsl.net/zl1bpu/FUZZY/History/History.html for overviews.
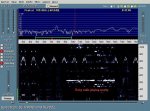
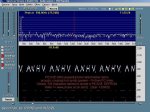
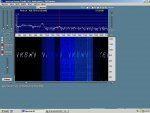
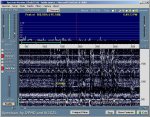
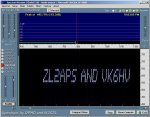
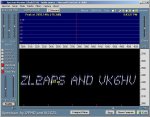
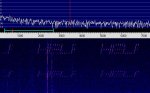
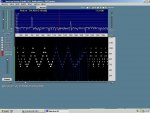
Dedicated soundcard based Hell decoding software abounds, but the simple use of (horizontal) "waterfall" spectral analysis displays, on the likes of particularly user friendly Spectran => http://digilander.libero.it/i2phd/spectran.html , readily allow the human eye to recognise patterns- see below. This sawtooth sample was simply acoustically coupled from a small speaker to a nearby PC mike, & even with a racous radio also playing was still quite visible.
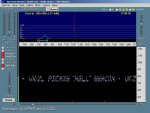
It's easy enough to 08M generate visible characters with suitably stepped SOUND commands (ref. code that produced the sawtooth), but of course these really eat into memory. The "sawtooth " ran to ~30 bytes on an 08M ! With at least 0-9 in mind, & of course as much of the alphabet as possible - perhaps in a simple 5x7 grid, efficient encoding techniques will be needed.
Discrete 110 -115 SOUNDs for this trial have just been used & of course the ~40-90 Hz gaps between each could be refined with suitable CALIBFREQ tweaks. I can think of diverse approaches using modular portions to assemble characters, but there are no doubt more cryptic ones the brains trust can offer. Anyone? TIA - Stan.
For those who've just come in, fuzzy mode "Hell" dates from 1929 & remains legendary for weak signal decoding, & is particularly well suited for very slow comms- often under the most ugly noise. Thanks to sound card decoding software Hellscreiber has had a terrific revitalisation with radio hams in the last decade, & new submodes have developed. See Murray's magnificent site=> http://www.qsl.net/zl1bpu/FUZZY/History/History.html for overviews.
Dedicated soundcard based Hell decoding software abounds, but the simple use of (horizontal) "waterfall" spectral analysis displays, on the likes of particularly user friendly Spectran => http://digilander.libero.it/i2phd/spectran.html , readily allow the human eye to recognise patterns- see below. This sawtooth sample was simply acoustically coupled from a small speaker to a nearby PC mike, & even with a racous radio also playing was still quite visible.
It's easy enough to 08M generate visible characters with suitably stepped SOUND commands (ref. code that produced the sawtooth), but of course these really eat into memory. The "sawtooth " ran to ~30 bytes on an 08M ! With at least 0-9 in mind, & of course as much of the alphabet as possible - perhaps in a simple 5x7 grid, efficient encoding techniques will be needed.
Discrete 110 -115 SOUNDs for this trial have just been used & of course the ~40-90 Hz gaps between each could be refined with suitable CALIBFREQ tweaks. I can think of diverse approaches using modular portions to assemble characters, but there are no doubt more cryptic ones the brains trust can offer. Anyone? TIA - Stan.
Code:
slowhelldemo:
sound 2, (110,100,111,100,112,100,113,100,114,100,115,100,116,100,115,100,114,100,113,100,112,100,111,100)
goto slowhelldemoAttachments
-
 108.5 KB Views: 109
108.5 KB Views: 109 -
 9 KB Views: 71
9 KB Views: 71
Last edited:
")